January 13, 2021
Merging split shapefiles scattered across different folders with arcpy
956 words | 4-min read |
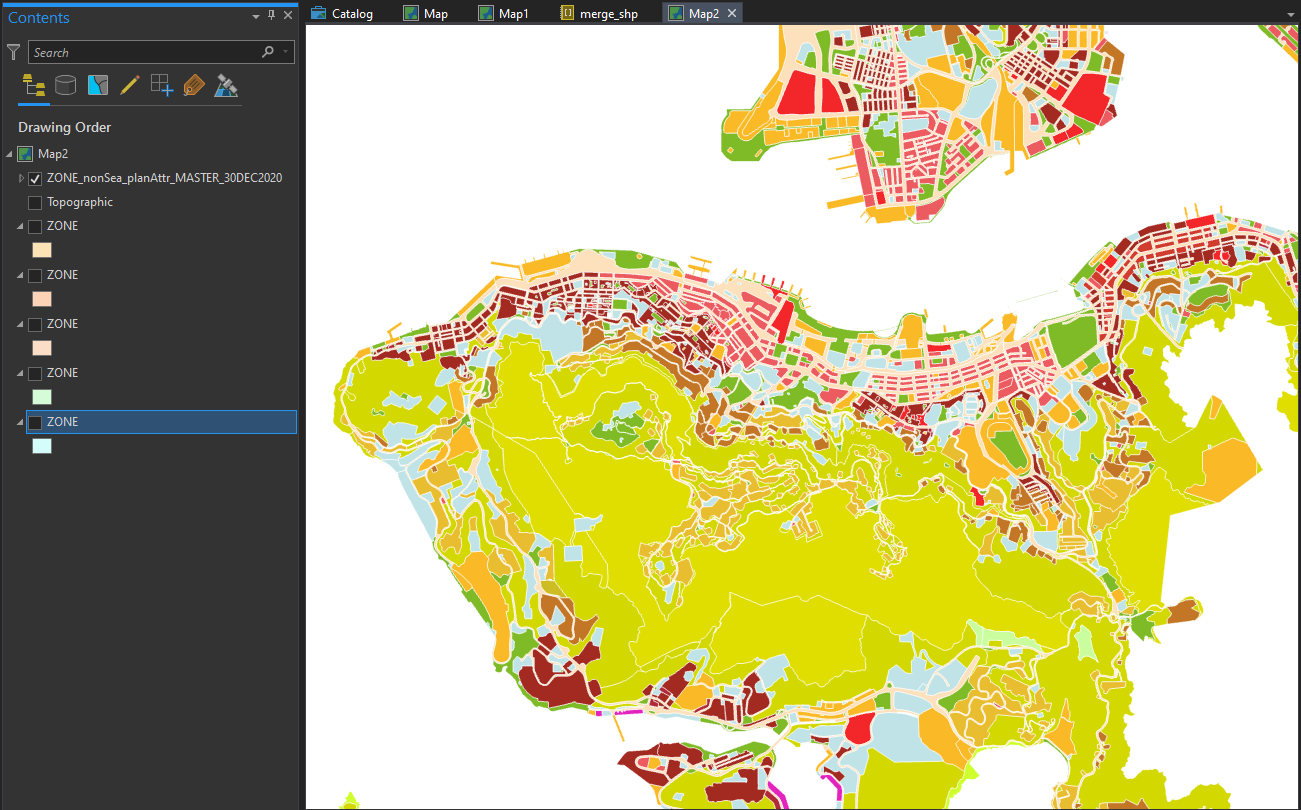
Land Use Zoning Shapefiles, split away
Although the Outline Zoning Plan (OZP) spatial data has became publicly available since mid 2019, the format of how Planning Department “open” the data is somehow troublesome for me - You have to download the data by planning scheme area one by one. There are around 160 planning scheme areas in Hong Kong - This means I have to manually download the zipped files 160 times. The cumbersome part does not end here - To get a territorial-wide zoning shapefile, I then have to merge those shapefiles back together.
File structure of the downloaded dataset
Each downloaded zip file is named with its respective planning scheme area. As mentioned above, there are around 160 sub-folders in this directory.
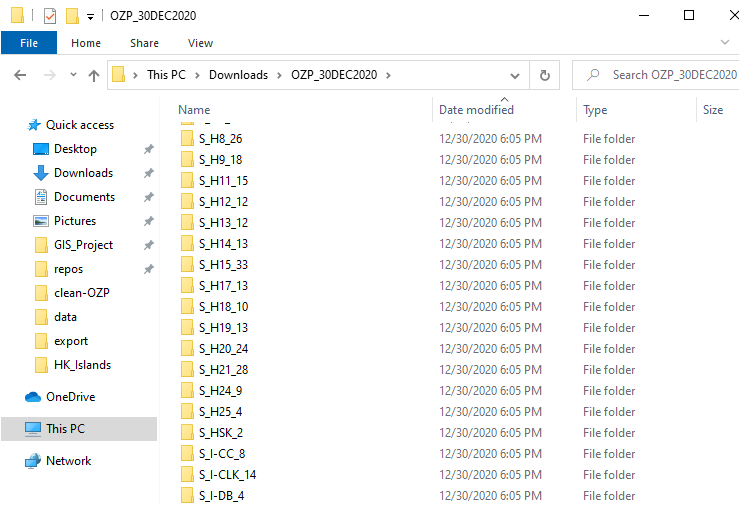
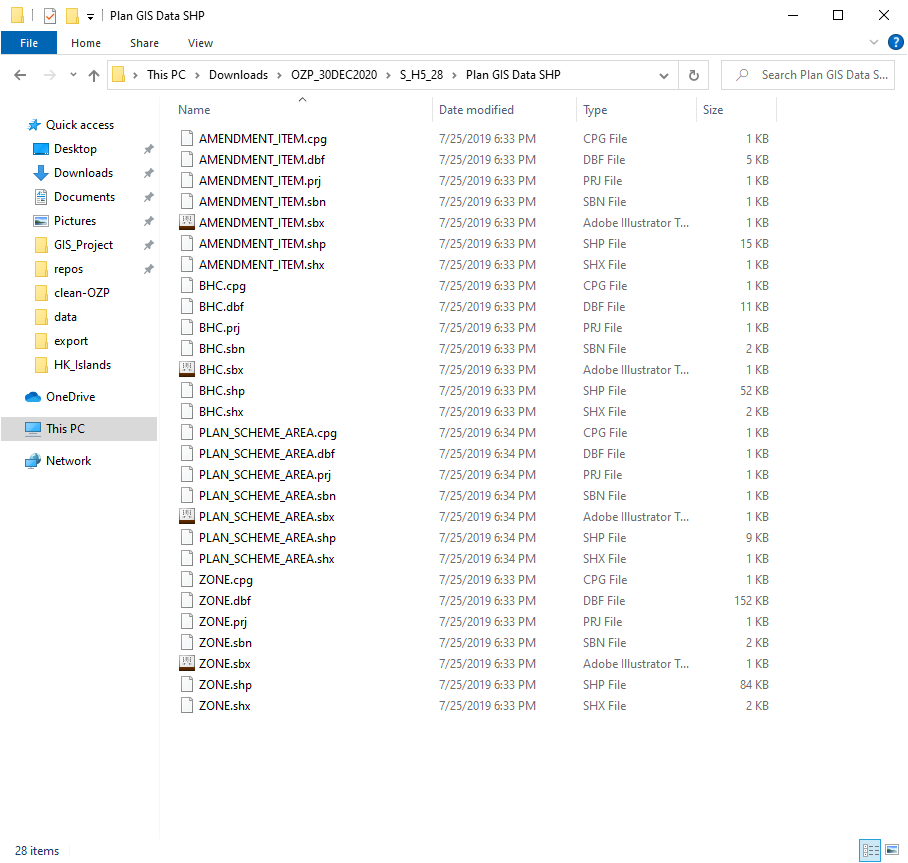
Inside the file, there’s a sub-directory called Plan GIS Data SHP, the files inside are the actual spatial digital planning data (though split) I am looking for. There are 4 layers provided:
- PLAN_SCHEME_AREA: planning scheme boundary of statutory plan
- ZONE: delineating the broad land use zonings within the Planning Scheme Area
- BHC: building height control areas as shown on plan and non-building area
- AMENDMENT_ITEM: amendments to matters shown on the plan
To say, following are the files I have to merge to get a territorial zoning map…
S_FLN_2/Plan GIS Data SHP/ZONE.shpS_FSS_24/Plan GIS Data SHP/ZONE.shpS_H3_34/Plan GIS Data SHP/ZONE.shp- …
- ~ 160 more shps
- …
S_H10_18/Plan GIS Data SHP/ZONE.shp
The shapefiles are just scattered in every sub-directory, with each of them “clipped” inside the planning scheme boundary.
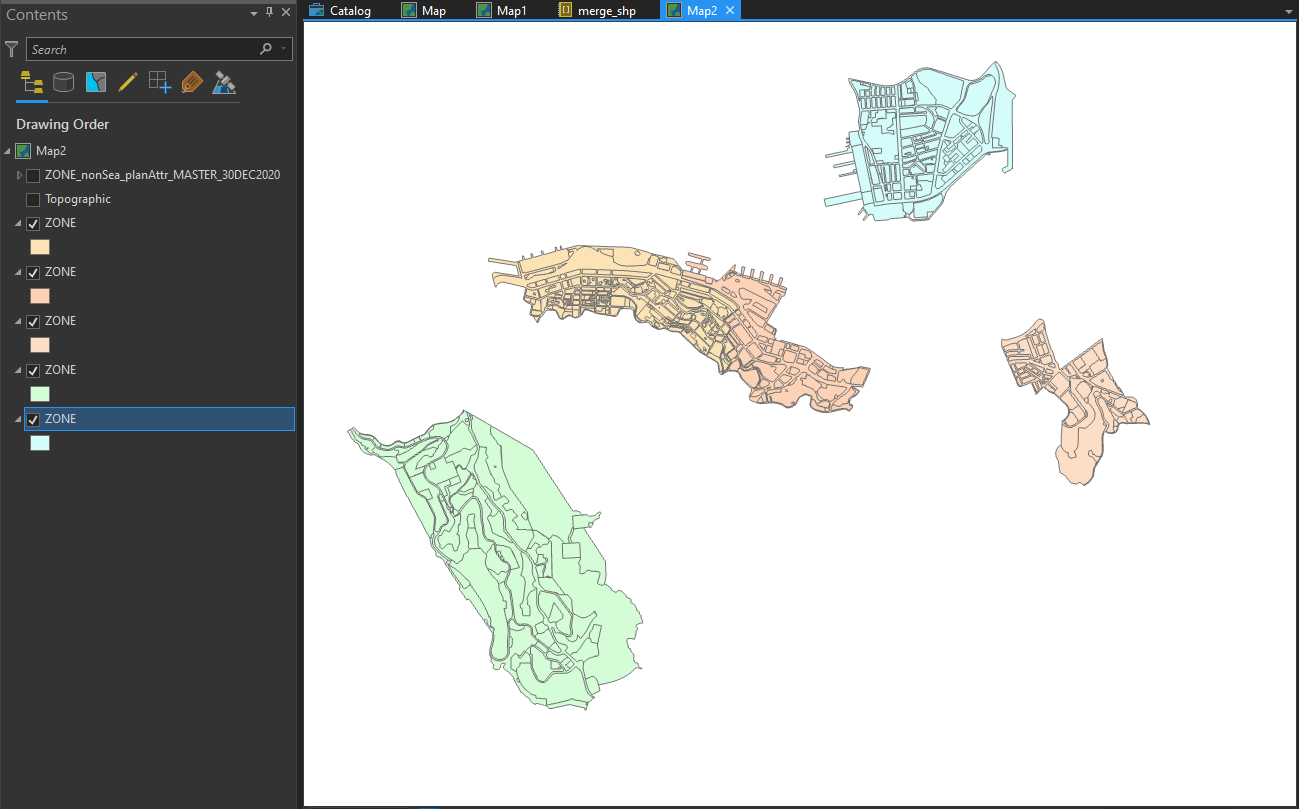
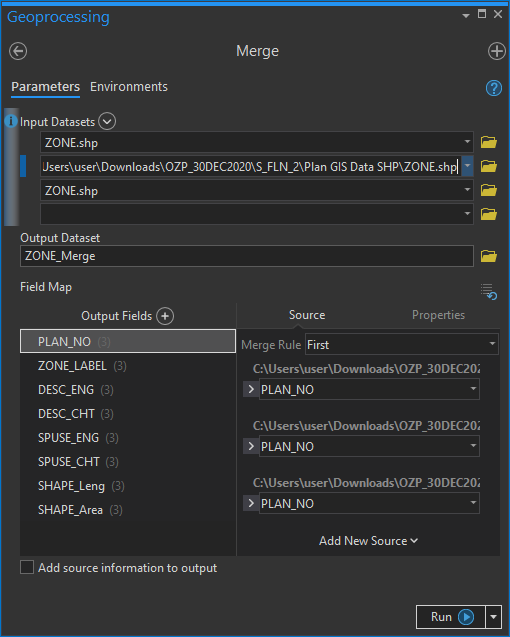
I am too lazy to manually click the buttons to add 160 files to the merge function in ArcGIS (I afraid the application will crash before the process). Therefore, I use arcpy.
Listing out all files using Python
import arcpy
import os
# set working space for arcpy
arcpy.env.workspace = path
os.listdir will list all directories in the given path
# the directory used to store all downloaded files
path = r"C:\Users\user\Downloads\OZP_30DEC2020"
directories = os.listdir(path)
Here’s what we have now when printing out the directories variable:
['S_FLN_2', 'S_FSS_24', 'S_H10_18', ........... ]
But this only gives an array of the directories “visible” from our
current path! Only having a string of S_H3_34 is not enough, as the
actual location of the shapefiles are inside the Plan GIS Data SHP
folder, which is inside the folder S_H3_34. This is what we actually
need:
['S_FLN_2\\Plan GIS Data SHP\\ZONE.shp', 'S_FSS_24\\Plan GIS Data SHP\\ZONE.shp', 'S_H10_18\\Plan GIS Data SHP\\ZONE.shp', ........... ]
The array is more about the same. The only difference is that each item in the array has a “suffix” pointing to the location of the shapefile.
We could create a new array to add this “file location suffix”.
SCHEMA_AREA_LOCATION and ZONE_LOCATION are two strings stating the
location of these two types of the shapefile relative to the working
directory. By adding this location as “suffix” of the file paths, we
could generate an array indicating the location of all
PLAN_SCHEME_AREA.shp.
SCHEMA_AREA_LOCATION = r'\Plan GIS Data SHP\PLAN_SCHEME_AREA.shp'
ZONE_LOCATION = r'\Plan GIS Data SHP\ZONE.shp'
directories_scheme_area = [dir + SCHEMA_AREA_LOCATION for dir in directories]
directories_zone = [dir + ZONE_LOCATION for dir in directories]
Merge them!
Finally, with the file list array generated, we can pass the whole array
to the arcpy.Merge_management to do all the merging jobs.
arcpy.Merge_management(directories_scheme_area, r"output\PLAN_SCHEME_AREA_master.shp")
arcpy.Merge_management(directories_zone, r"output\ZONE_master.shp")
We then have a continuous zoning polygon for the whole Hong Kong.
When shapefiles only exist in several folders
Things are little bit more tricky for special files of BHC (Building
Height Control) and AMENDMENT_ITEM (Amendment Items in the new draft
OZP). These two items are available only in some plans. If the plan does
not have any building height stipulated. The BHC.shp does not exist.
If we pass a file that does not exist to arcpy.Merge_management, the
function will throw an error.
Therefore, we need to first check if BHC shapefile exist in that
planning scheme area. In the arcpy module there’s a function named
Exists, which will check the existence of an file. Documentation of
the function is in ESRI’s
website.
Here I initialised a new array directories_bhc_exist to store the
directories where BHC.shp actually exist. arcpy.Exists returns True if
the file with the given file path exist. Thus, only file paths with the
file actually exist will be appended (i.e. added) to the new array.
BHC_LOCATION = r'\Plan GIS Data SHP\BHC.shp'
directories_bhc = [dir + BHC_LOCATION for dir in directories]
directories_bhc_exist = []
for bhc_shp in directories_bhc:
if arcpy.Exists(bhc_shp):
directories_bhc_exist.append(bhc_shp)
As a quick check, we could find the length of the two arrays. The
directories_bhc_exist array should be shorter since we discarded those
non-exist BHC shapefile paths. There are about half of the plans do not
have any building height stipulated on the plan. Most of them are rural
plans.
len(directories_bhc) # 165
len(directories_bhc_exist) # 77
And then we could merge the files.
arcpy.Merge_management(directories_bhc_exist, "output\BHC_master.shp")
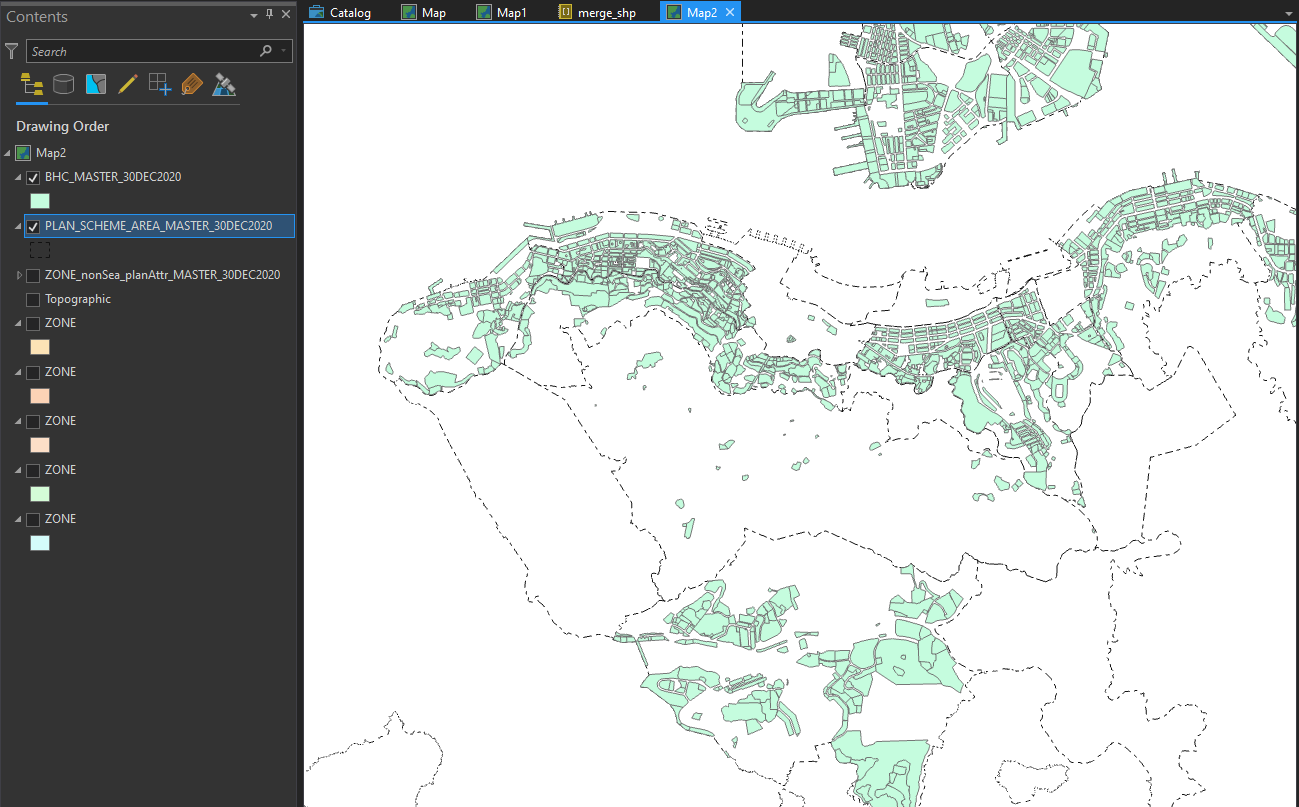
Below shows the ares with building height control stipulated on the gazetted plan. some of the plans like Pokfulam (H10) do not have any building height control stipulated. (possibly related to Pokfulam Moratorium).
The same for the AMENDMENT_ITEM feature class.
directories_amendment_exist = []
for amendment_shp in directories_amendment:
if arcpy.Exists(amendment_shp):
directories_amendment_exist.append(amendment_shp)
arcpy.Merge_management(directories_amendment_exist, "output\BHC_master.shp")
Any better ways?
Theoretically, the best practice is to use try and then catch all
possible arcpy errors. But I am a bit lazy to do that since I already
know how the files are stored.
However, what if the shapefiles do not always have the same location?
There may have one ZONE.shp located in PLAN_A/Plan GIS Data SHP/ZONE.shp, while another in PLAN_B/another_subfolder/Plan GIS Data SHP/more_subfolder/ZONE.shp. Could we improve scripts by
recursively searching for the specified files until we find that
file? I am thinking of building some pipeline functions to automatically
merge OZP shapefiles, yet that will be another story…